Kafka基础概念
使用场景
作为消息系统(Kafka as a Messaging System)
作为存储系统(Kafka as a Storage System)
流处理(Kafka for Stream Processing)
主题和日志
主题是会被推送记录的一个类别或订阅名称
对于每一个主题,Kafka维护了一个分区日志群集!

每个分区是一个有序的,可以不断追加消息的消息序列。分区中的每个消息都会分配一个在分区内是唯一的序列号,这个序列号叫做偏移量(offset)
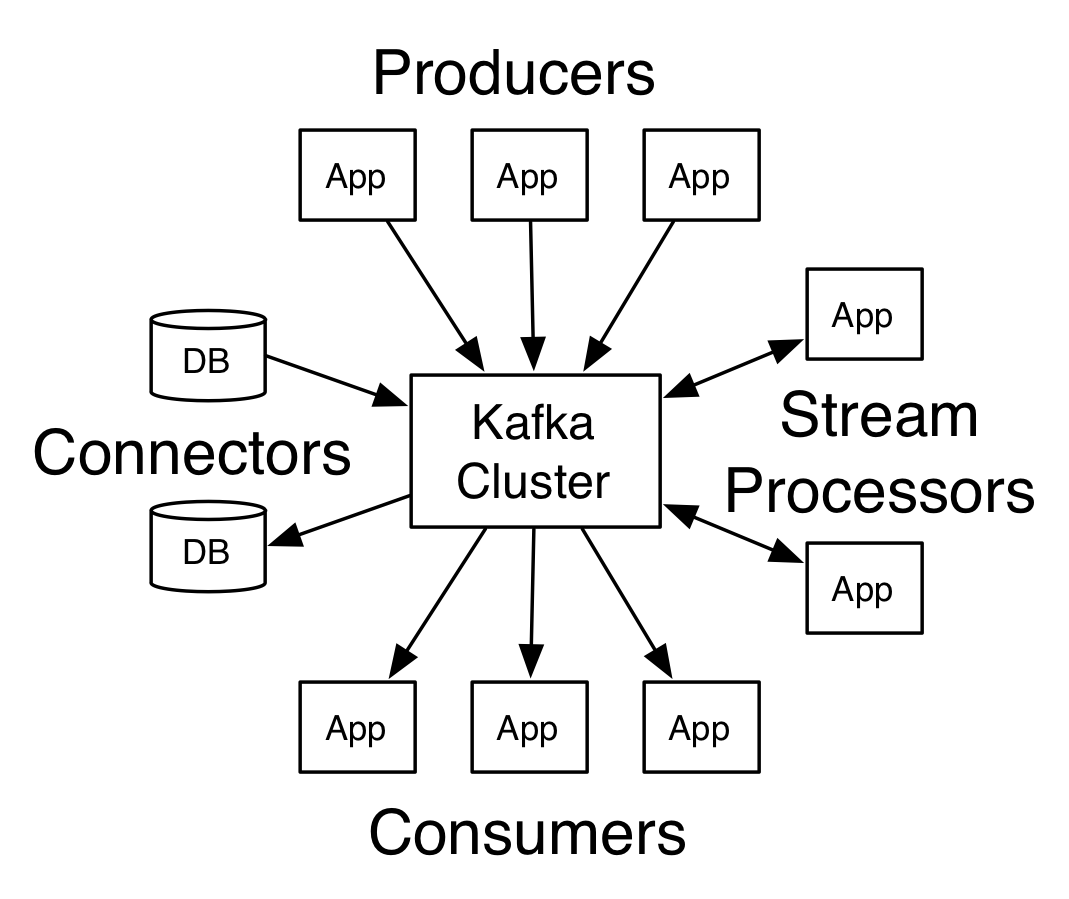
核心API
PRODUCER API
允许应用推送流记录到一个或多个Kafka主题上。
生产者向所选的主题发布数据。生产者负责选择哪些消息应该分配到主题内的哪个分区。这种选择分区方式,可以使用简单的循环方式负载均衡; 也可以通过一些语义分区函数实现(如:基于消息的key进行划分)。
CONSUMER API
允许应用程序订阅一个或多个主题并且并处理产生的流记录
每个消费者都属于一个消费组,每一条被推送到主题的记录被传递给订阅该主题的消费组的其中一个消费者。消费者可以在不同进程或者不同的机器上。
如果所有的消费者实例有相同的消费组,消息将会有效地负载平衡给这些消费者实例。
STREAMS API
允许应用程序作为一个流处理器,从一个或多个主题获取流数据,然后输出流数据到一个或多个主题,有效地将输入流转换为输出流。
如果所有的消费者实例在不同的消费组中,那么每一条消息将会被广播给所有的消费者处理。
CONNECTOR API
允许构建和运行可重用的生产者(Producer)或消费者(Consumer)连接Kafka与现有应用程序或数据系统。例如,一个连接器(connector)在关系数据库中可能获取每个表变化。
逻辑图