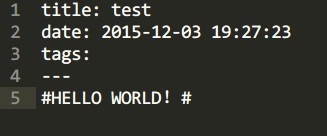
> npm install
npm WARN optional dep failed, continuing fsevents@0.3.8
npm WARN optional dep failed, continuing fsevents@1.0.5
|
> dtrace-provider@0.6.0 install *HEXO_HOME*\node_modules\hexo\node_modules\buny
an\node_modules\dtrace-provider
> node scripts/install.js
hexo-generator-category@0.1.3 node_modules\hexo-generator-category
├── object-assign@2.1.1
└── hexo-pagination@0.0.2 (utils-merge@1.0.0)
hexo-generator-index@0.1.3 node_modules\hexo-generator-index
├── object-assign@2.1.1
└── hexo-pagination@0.0.2 (utils-merge@1.0.0)
hexo-generator-tag@0.1.2 node_modules\hexo-generator-tag
├── object-assign@2.1.1
└── hexo-pagination@0.0.2 (utils-merge@1.0.0)
hexo-generator-archive@0.1.3 node_modules\hexo-generator-archive
├── object-assign@2.1.1
└── hexo-pagination@0.0.2 (utils-merge@1.0.0)
hexo-server@0.1.2 node_modules\hexo-server
├── object-assign@2.1.1
├── open@0.0.5
├── mime@1.3.4
├── bluebird@2.10.2
├── chalk@0.5.1 (ansi-styles@1.1.0, escape-string-regexp@1.0.3, supports-colo
r@0.2.0, strip-ansi@0.3.0, has-ansi@0.1.0)
├── morgan@1.6.1 (on-headers@1.0.1, basic-auth@1.0.3, depd@1.0.1, on-finished
@2.3.0, debug@2.2.0)
├── serve-static@1.10.0 (escape-html@1.0.2, parseurl@1.3.0, send@0.13.0)
├── connect@3.4.0 (parseurl@1.3.0, utils-merge@1.0.0, debug@2.2.0, finalhandl
er@0.4.0)
└── compression@1.6.0 (bytes@2.1.0, vary@1.1.0, on-headers@1.0.1, compressibl
e@2.0.6, debug@2.2.0, accepts@1.3.0)
hexo-renderer-stylus@0.3.0 node_modules\hexo-renderer-stylus
├── stylus@0.52.4 (css-parse@1.7.0, debug@2.2.0, mkdirp@0.5.1, source-map@0.1
.43, glob@3.2.11, sax@0.5.8)
└── nib@1.1.0 (stylus@0.49.3)
hexo-renderer-marked@0.2.5 node_modules\hexo-renderer-marked
├── object-assign@2.1.1
├── marked@0.3.5
├── strip-indent@1.0.1 (get-stdin@4.0.1)
└── hexo-util@0.1.7 (ent@2.2.0, bluebird@2.10.2, highlight.js@8.9.1)
hexo@3.1.1 node_modules\hexo
├── hexo-front-matter@0.2.2
├── pretty-hrtime@1.0.1
├── abbrev@1.0.7
├── archy@1.0.0
├── titlecase@1.0.2
├── text-table@0.2.0
├── strip-indent@1.0.1 (get-stdin@4.0.1)
├── tildify@1.1.2 (os-homedir@1.0.1)
├── chalk@1.1.1 (escape-string-regexp@1.0.3, supports-color@2.0.0, ansi-style
s@2.1.0, strip-ansi@3.0.0, has-ansi@2.0.0)
├── hexo-i18n@0.2.1 (sprintf-js@1.0.3)
├── minimatch@2.0.10 (brace-expansion@1.1.2)
├── through2@1.1.1 (xtend@4.0.1, readable-stream@1.1.13)
├── bluebird@2.10.2
├── swig-extras@0.0.1 (markdown@0.5.0)
├── moment-timezone@0.3.1
├── js-yaml@3.4.6 (inherit@2.2.2, esprima@2.7.0, argparse@1.0.3)
├── warehouse@1.0.3 (graceful-fs@4.1.2, cuid@1.2.5, JSONStream@1.0.7)
├── nunjucks@1.3.4 (chokidar@0.12.6, optimist@0.6.1)
├── cheerio@0.19.0 (entities@1.1.1, dom-serializer@0.1.0, css-select@1.0.0, h
tmlparser2@3.8.3)
├── moment@2.10.6
├── hexo-cli@0.1.9 (minimist@1.2.0, bluebird@3.0.6)
├── lodash@3.10.1
├── swig@1.4.2 (optimist@0.6.1, uglify-js@2.4.24)
├── hexo-util@0.1.7 (ent@2.2.0, highlight.js@8.9.1)
├── bunyan@1.5.1 (safe-json-stringify@1.0.3, dtrace-provider@0.6.0, mv@2.1.1)
└── hexo-fs@0.1.5 (escape-string-regexp@1.0.3, graceful-fs@4.1.2, bluebird@3.
0.6, chokidar@1.3.0)